
Memory Is State, Not a Service

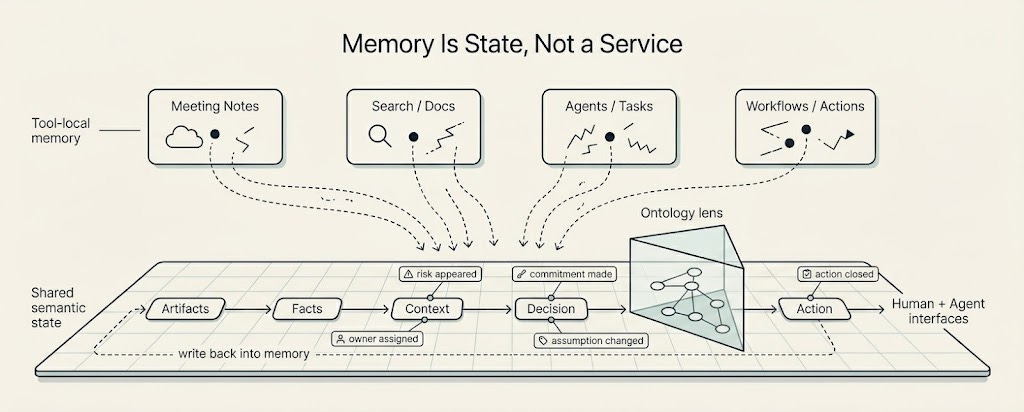
Every AI tool now wants to remember. Meeting recorders remember conversations, search products remember documents, agents remember tasks, and workflow systems remember actions. That sounds like progress, but it may be making the real problem worse. If every tool remembers separately, the company still forgets.
A Company Brain needs a different architecture: memory as shared state, not memory as a service.
Humans have always patched over fragmented company memory through conversations, intuition, backchannels, and recurring meetings. We remember which customer was angry, what a PM promised, why a deal was risky, why a roadmap item moved, and which decision was made for reasons that never made it into the document. Agents do not have that luxury. They act from whatever state they can access. If that state is stale, partial, or private to one tool, their reasoning inherits the fragmentation. AI adoption makes this more dangerous. Every local memory becomes a local truth.
The three memories I have described in this series only work if they are three views of one state. Factual memory cannot be trapped in enterprise search. Interaction memory cannot live only in meeting notes. Action memory cannot disappear inside workflow tools or agent traces. If those three layers become three separate products, the substrate has already split, and everything built on top of it inherits that split.
This is the architectural center of Company Brain. Memory should not sit inside one app’s API, one vector index, one database, one agent scratchpad, or one meeting recorder. The company has to be able to inspect it, correct it, version it, permission it, and move it. Otherwise every tool remembers a little, but the company itself still forgets.
The substrate has to include the obvious artifacts: people, teams, customers, projects, documents, tickets, emails, meetings, dashboards, and actions. But useful company memory is rarely the artifact alone. It also has to include relationships, events, facts, decisions, commitments, assumptions, outcomes, provenance, permissions, and history. A database stores records. A substrate defines the rules by which records become shared operating state.
Storage is no longer the hard question. The hard question is how a piece of data becomes context, and that is where ontology becomes central. An ontology is the lens that tells a system what kinds of things exist, how they relate, and what they can mean. The same artifact can mean very different things depending on the ontology applied to it.
Take a customer email. The raw artifact is the same for everyone: sender, recipients, timestamp, subject, body, attachments. To sales, that email is renewal risk. To product, it is a roadmap signal. To support, it is an escalation. To legal, it is an obligation. To finance, it is revenue exposure. To a CEO, it is strategic account risk. To an agent, it is an action trigger. The data did not change. The lens did. Humans do this naturally and constantly. They hear the same sentence differently depending on the customer, the project, the speaker, the history of the account, and what happens if the interpretation is wrong. A Company Brain cannot treat context as a single fixed label attached to an artifact. The same artifact has to be readable through different ontologies depending on the role, the question, the moment, and the action being considered.
This is also what makes context graphs useful. A context graph should not be everything connected to everything else, because that produces a hairball. A useful context graph is shaped by ontology: which entities exist, which relationships matter, which events should be remembered, and which parts of an artifact become durable memory. The ontology is the lens. The context graph is what the lens makes visible.
The lifecycle of a single customer complaint is the shape of what the substrate has to hold. The complaint arrives in email, gets discussed in Slack, shows up in a PM meeting, updates a support ticket, gets linked to an engineering issue, and causes sales to mark the account as a renewal risk. Someone promises a follow-up by Friday. Later the risk either resolves, escalates, or quietly becomes part of the next roadmap discussion.
The memory is not the email, the ticket, the meeting note, the Slack thread, or the engineering issue. The memory is the state change the complaint caused: what became true, who now owns it, why it mattered, which commitments were created, what action followed, and whether the company later learned from the outcome. State changes have to be first-class. A Company Brain has to remember that something changed: a risk appeared, an owner was assigned, a commitment was made, an assumption became false, a decision depended on a claim, or an action closed the loop.
I have been calling the abstraction we are building toward a semantic memory filesystem. The filesystem metaphor is useful because files have properties people understand: paths, ownership, inspection, version history, and portability. The semantic part is what changes. In our model, the primitives are not just files. They are entities (people, teams, customers, projects), facts (atomic claims with provenance), state changes (the events that move company state forward), and relationships (typed edges that carry meaning, not just adjacency). Ontologies sit above this layer as lenses, not below it as schemas, which is what lets the same underlying memory be read differently by sales, product, legal, and an agent without the memory itself splitting into copies.
That is the abstraction. The implementation has to do more than this. It has to support exact retrieval when someone is looking for a clause in a contract. It has to support semantic retrieval when the question is asked in words nobody used at the time. It has to support graph traversal when the answer lives in relationships, time, or permissions. And it has to support state change as a query, because the most useful question is often not “what is this” but “what changed and why.”
The human and agent duality is the other reason this architecture matters. Humans need to inspect memory, correct it, and see what changed. Agents need to query it, update it, follow permissions, and act from it. If they do not share the same substrate, the system splits again: humans have docs, agents have scratchpads, and the company still does not have memory.
Trust becomes the real test. The substrate has to answer boring questions that are not actually boring. Where did this memory come from? Who can see it? Who changed it? Is it still current? What contradicts it? What action was taken from it? Can a human correct it? Without those answers, memory becomes another black box.
When the substrate works, it can show up differently for different people without becoming different memory. An IC may experience it as context for the task in front of them. A manager may see commitments, blockers, handoffs, and unresolved decisions. A CEO may see where the company is acting from inconsistent assumptions. An agent may see operating state: what is true, why it matters, what can be done, and what should be written back. Same memory, different interfaces.
A semantic memory substrate does not remove judgment, politics, ambiguity, or the work of deciding what matters. Companies are still human systems. The substrate is what makes their memory legible enough that the human work is not constantly being repeated.
There is a real open question I do not yet know the answer to: does one substrate generalize across verticals, or does each vertical need its own? The bet I am making is that the substrate generalizes and the ontologies on top of it do not. Sales, product, support, legal, and finance need their own lenses, but they should be looking at the same memory. Whether that bet holds is something the next year of building will answer. The next part of this series is about the lens layer, which is where adoption either compounds or fragments.
—-
At Sentra, where we are building enterprise general intelligence: a shared intelligence/memory layer that sits on all communication channels, knowledge bases and agent traces to understand how everyone in an organization actually works as well as how work actually gets done, constructing a living world model of the entire company in near real time.
I was putting together a hypothesis for a Centralised Enterprise memory solution. Thought of abstraction layer at each stage upwards
Reminds me of "If there are epigrams, there must be meta-epigrams."
https://gwern.net/doc/cs/algorithm/1982-perlis.pdf